
Moving away from Vector-based architectures…
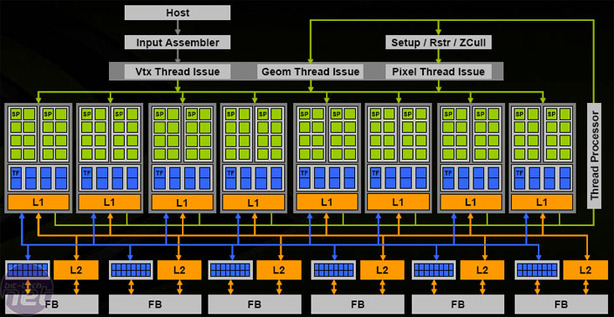
At the heart of NVIDIA’s GeForce 8800-series architecture, there are up to 128 scalar stream processors designed to perform all of the shader operations sent to the GPU. Each of the scalar stream processors is capable handling both floating point and integer calculations.G80’s ALU’s (arithmetic and logic units) are 1D scalar units, meaning that each one is capable of handling one scalar instruction per clock. They are also compliant with the IEEE 754 floating point precision standard, while also being fully generalised, fully decoupled and capable of dual-issue of a scalar MAD and a scalar MUL instruction in the same clock cycle.
In the past, GPU’s have used vector processing units because a lot of operations in graphics use vector data. However, there are also a large number of scalar operations occurring too.
The reason behind the move away from a vector-based architecture is two fold. Firstly, it’s hard to fully utilise all processing units all of the time, which ultimately means wasted silicon and wasted clock cycles. And second, it’s also incredibly difficult to compile and schedule scalar operations in vector pipelines. Because the stream processors are scalar, the GPU is able to convert any vector-based shader programme code into scalar operations and the data is split across multiple stream processors to ensure high efficiency levels.
G80 - pipeline flow diagram
Shader & Texture Units:
The GeForce 8800 GTX GPU includes 128 1D scalar stream processing units clocked at 1.35GHz split into clusters of 16 shader processors. GeForce 8800 GTS includes only 96 1D scalar stream processors, and they’re clocked lower at 1.2GHz – the layout is exactly the same as GeForce 8800 GTX though, with just one quarter of the shader processors disabled in hardware.Although the stream processors are completely decoupled, they share L1 and L2 cache in eight 16-shader clusters. The clusters of sixteen streaming processors also share four texture address units and eight texture filtering units, making up a total of 32 texture address units and 64 texture filtering units in GeForce 8800 GTX. These are clocked at a different speed to the stream processors. The texture address and texture filtering units are clocked at what NVIDIA determines the actual core clock to be – that’s 575MHz on GeForce 8800 GTX. The ROPs are also clocked at this speed, too – we'll come to that portion of the GPU shortly.
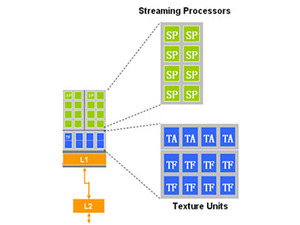

On top of this, the texture units are completely decoupled from the streaming processors, meaning that it’s possible to texture filter while continuing to progress through other shader operations. This is another area where NVIDIA has improved its performance and more importantly efficiency because the streaming processors are never left to idle if there are math operations to be calculated. Not only that, but the texture units are optimised for HDR and support both FP16 and FP32 texture formats.
In contrast, GeForce 7-series uses the first shader unit as the texture address unit too, meaning that it’s impossible for the ALU to process shader instructions while it’s doing a texture address. By making that trade off, NVIDIA saved some die space, but at the expense of performance in some situations – for example, anisotropic texture filtering – where both shader units would completely stall until the texture filtering had been completed.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.